EvalC3 Online: Thinking about Model Performance
There are many different ways of analysing the performance of a predictive model (aka classifier).
See this link for a detailed overview of a confusion matrix.
There is no single correct / best measure that is suitable for all situations. The choice of measure to use depends on at least two things:
1. The nature of the data set being analysed: How are the outcome values distributed
2. The context in which the analysis is needed: How important it is to minimise FPs versus FNs
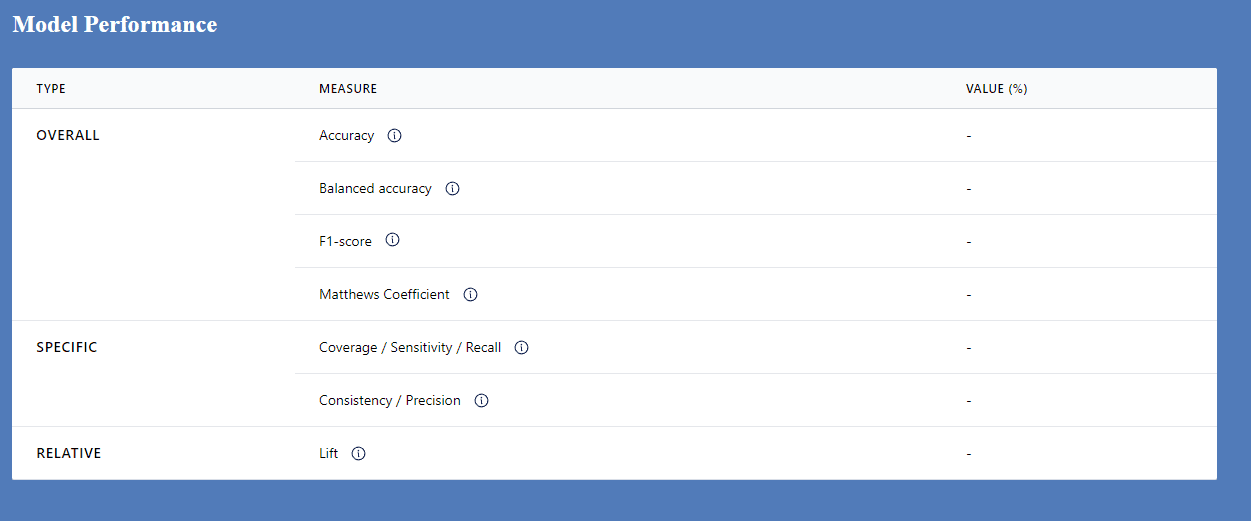
Overall measures
Data sets can be balanced or unbalanced. A balanced data set has an even proportion of cases where the outcome is present and absent e.g. 50% . Here the use of Classification Accuracy (TP+TN)/(TP+TN+FP+FN) is appropriate
Balanced Accuracy ((TP/(TP+FN) + (TN/TN+TP))/2 is the better option when the data set is unbalanced e.g 25% vs 75%. But if the costs of the two types of errors (FP, FN) are different then it would better to move to Balanced Accuracy at a lower threshold e.g 60%
The F1 score and the Mathews Coefficient are both used when you want to minimise both kinds of errors (FP and FN) equally, not favoring one over the other. On balance, the Mathews Coefficient seems the better chocie, because, as explained by Perplexity AI:
- Balanced metric: MCC takes into account all four possible outcomes of a binary classification.
- Class distribution independent: MCC is independent of the class distribution and prevalence of the positive class.
- Intuitive interpretation: MCC ranges from -1 to 1, where 1 is perfect classification, 0 is random guessing, and -1 is completely wrong classification.
- Robust performance: MCC often provides a more truthful and informative score compared to accuracy and F1, especially in imbalanced scenarios.
- Invariant to class swapping: Unlike F1, MCC remains the same if the positive and negative classes are swapped.
Specific measures, where relevance depends on context
Consistency / Precision (TP/TP+FP) should be used where FP errors need to be minimised, because of their cost. For example a surgeon wants a model that will help deliver the expected outcome with the absolute minimum possibility of patient death
Coverage / Sensitivity / Recall (TP/TP+FN) are important when the cost of FPs is not a big concern. An investor may be willing to tolerate a number of failed investments, if those that do succeed deliver enough profit to more than cover the costs of the failed investments. They are likely to be looking for a predictive model that has a wider applicability i.e high coverage.
Relative measures
Lift measures how much better a model is at predicting the positive class compared to a random baseline: (TP/(TP+FN)) / ((TP+FP)/(TP+TN+FP+FN)). A lift of 100% means the model performs no better than random chance. A lift greater than 100% indicates the model is performing better than random. Higher lift values mean stronger model performance.
